ysoserial学习与实践(一)
ysoserial:A proof-of-concept tool for generating payloads that exploit unsafe Java object deserialization.
一款用于生成Java反序列化漏洞Payload的POC工具。
奶活我的博客。
前置:序列化与反序列化
本系列的计划为:一篇前置(序列化与反序列化与反序列化漏洞);一至多篇调用链分析;一至两篇ysoserial实践。
序列化机制
序列化(Serialization)指将数据结构或者对象状态转换成字节流(存储文件/内存缓冲,或经由网络传输),后续可以在相同环境下,恢复到原来状态的过程。
如下为一个Java序列化示例:
1 | public class SerializationDemo implements Serializable { |
这样就完成了序列化过程,可以把结果输出到文件中观察一下:
1 | import java.io.*; |
按Java的标准约定是给文件一个.ser扩展名,但是写bin之类的都无所谓,得到序列化结果的二进制串:
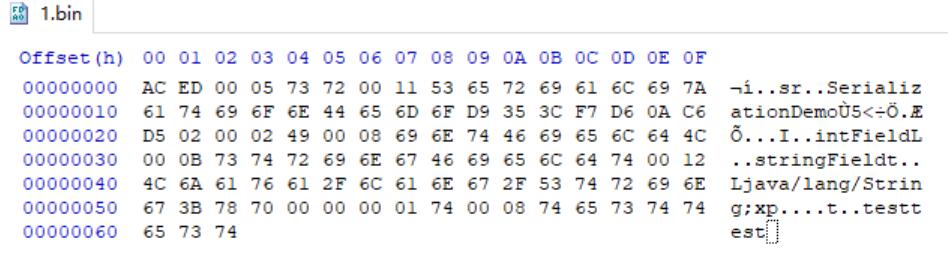
解读此二进制串中的各个元素:
0xACED,魔术头
0x0005,版本号(JDK主流版本一致,此处为JDK8u)
0x73,对象类型标识,详见java.io.objectStreamConstants
0x72,类描述符标识
0x0011...,类名字符串长度+值
0xD9353CF7D60AC6D5,序列版本唯一标识(SerialVersionUID,简称SUID)
0x02,对象的序列化属性标志位(是否Block Data模式,自定义writeObject(),Serializable、Externalizable、Enum等类型)
0x0002,类的字段个数
0x49,整数类型签名的第一个字节,同理,后面的0x4C为字符串类型签名的第一个字节(同JVM规范)
0x0008...,字段名字符串长度+值,非原始数据类型的字段还会在后面加上数据类型标识、完整类型签名长度+值,如本行最后的0x740012...
0x78,Block Data结束标识
0x70,父类描述符标识,此处为Null
之后则为整数字段和字符串字段的值等。需要注意,Java序列化中对字段进行封装时,会按照原始和非原始数据类型排序,且这其中又会按字段名排序。
简析一下序列化的执行流程:
1、
ObjectOutputStream实例初始化时,将魔术头和版本号写入bout(BlockDataOutputStream类型)中
2、调用
ObjectOutputStream.writeObject()准备写对象数据
3、
ObjectStreamClass.lookup()封装待序列化的类描述(返回ObjectStreamClass类型),获取包括类名、自定义serialVersionUID、可序列化字段(返回ObjectStreamField类型)和构造方法,以及writeObject、readObject方法等
4、
writeOrdinaryObject()写入对象数据
5、写入对象类型标识
6、
writeClassDesc()进入分支writeNonProxyDesc()写入类描述数据
7、(依次)写入类描述符标识、写入类名、写入SUID(为空时计算)、计算并写入序列化属性标志位、写入字段信息数据、写入Block Data结束标识、写入父类描述数据
8、
writeSerialData()写入对象的序列化数据
9、若类自定义了
writeObject(),则调用该方法写对象,否则调用defaultWriteFields()写入对象的字段数据(非原始类型则递归处理子对象)
序列化机制的应用场景主要有两种:
1)服务器启动后,一般不会关闭,但是如果遇到需要重启的情况,而用户会话还在进行相应的操作,这时就需要使用序列化将session信息保存起来放在硬盘,服务器重启后,又重新加载。这样就保证了用户信息不会丢失,实现永久化保存。
2)在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,存入物理硬盘,以便减轻内存压力或便于长期保存。
反序列化机制
继续看一个简单的示例:
1 | public static void main(String[] args) throws ClassNotFoundException { |
直接分析执行流程:
1、
ObjectInputStream实例初始化时,读取魔术头和版本号进行校验
2、调用
ObjectInputStream.readObject()开始读对象数据
3、读取对象类型标识
4、
readOrdinaryObject()读取数据对象
5、
readClassDesc()读取类描述数据
6、读取类描述符标识,进入分支
readNonProxyDesc()
7、(依次)读取类名、读取SUID、读取并分解序列化属性标志位、读取字段信息数据
8、
resolveCLass()根据类名获取待反序列化的类的Class对象,如果获取失败,则抛出ClassNotFoundException
9、
skipCustomData()循环读取字节直到Block Data结束标识为止
10、读取父类描述数据
11、
initNonProxy()判断对象与本地对象的SUID和类名(非包名)是否相同,若不同则抛出InvalidClassException
12、
ObjectStreamClass.newInstance()获取并调用离对象最近的非Serializable的父类无参构造方法(无则null)创建对象实例
13、
readSerialData()读取对象的序列化数据
14、若类里自定义了
readObject(),则调用该方法都对象,否则调用defaultReadFields()读取并填充对象的字段数据
SUID相当于一个对象的指纹信息,可以直接决定反序列化的成功与否。关于SerialVersionUID的生成或计算过程,由于稍微繁琐且意义不太大,暂时不做分析,感兴趣的同好可以翻阅一下官方文档。
反序列化漏洞
通过构造恶意输入,控制待反序列化的内容,使其反序列化产生非预期的对象,由此造成任意代码执行。
看上节反序列化机制中的代码,假设那就是服务端的代码。其通过readObject来读取序列化后的数据,如果客户端提交的数据中序列化了如下代码:
1 | public class GadgetObject implements Serializable { |
即支持序列化后重写了readObject方法,使用defaultReadObject指定为默认读取方法,再调用Runtime的exec实现外部命令。
提前介绍一些关于Apache Commons Collections的内容,下一篇详细分析调用链。
Apache Commons Collections 是一个扩展了Java标准库里的Collection结构的第三方基础库。
org.apache.commons.collections提供一个类包来扩展和增加标准的Java的collection框架,这些扩展也属于collection的基本概念,但是极大地扩展了其功能。